개발할때 확실히 도움이 되는 tip!!
잘난척 하지 말고 꼭 보시길~
https://blog.jetbrains.com/idea/2023/02/debugger-upskill-stepping/

기술로 건전한 콘텐츠 발굴, 모두가 누릴수 있는 행복한 세상
개발할때 확실히 도움이 되는 tip!!
잘난척 하지 말고 꼭 보시길~
https://blog.jetbrains.com/idea/2023/02/debugger-upskill-stepping/
| 구분 | database | schema |
|---|---|---|
| shared schema | O | O |
| shared database | O | X |
| different database | X | NA |
각각의 방법은 장단점이 있으며 여기 논하지 않는다.
shared schema는 tenant가 구분되어야 할 entity에 대한 독립성 유지을 유지해야 하며,
코드 수준에서 설계된 시스템은 정보유출 위험이 생길 수 밖에 없다.
그러므로, framework 수준에서 tenant를 독립성을 보장할 수 있는 방법으로 구현해야한다.
다음은 hibernate 6을 통해 쉽게 shared schema 를 구현하는 코드의 일부이다.
@TenantId를 사용하여 entity class에 테넌트로 구분할 필드를 정의한다.
@Entity
@Table
public class Owner {
@Id
@GeneratedValue
@Column(name = "id", nullable = false)
private Long id;
@Column(name = "name")
private String name;
@TenantId
@Column(name = "tenant")
private String tenant;
}
다음은 @TenantId 로 정의된 entity에 대하여 CRUD가 발생되는 경우 tenant정보를 추출하는 component 이다
@Component
public class TenantIdentifierResolver implements CurrentTenantIdentifierResolver, HibernatePropertiesCustomizer {
@Override
public String resolveCurrentTenantIdentifier() {
return .. // 세션,토큰,requset 등에서 tenant 정보를 추출;
}
@Override
public void customize(Map<String, Object> hibernateProperties) {
hibernateProperties.put(AvailableSettings.MULTI_TENANT_IDENTIFIER_RESOLVER, this);
}
}

주요 생성형 AI 서비스에는 다음과 같은 것들이 있습니다:
브라우즈 AI(Browse AI) : 웹사이트 모니터링
클립드롭(ClipDrop) : 지능형 디자인 도우미
컴포즈 AI(Compose AI) : 이메일 응답
데스크립트 오버덥 : 음성 복제
D-ID.com : 실시간 비디오 제작
듀러블(Durable) : 30초만에 웹 사이트 구축
카이버(Kaiber) : 설명만 하면 만들어지는 애니메이션
노션 AI(Notion AI) : 지능형 협업
픽토리(Pictory) : 비디오 편집을 위한 만능 툴
Rewind.ai : 맥에서만 가능한 되감기 기능
런웨이(Runway) : 손쉬운 동영상 조작
신세시아(Synthesia) : 전문가를 위한 빠른 비디오 제작
토움(Tome) : 버튼 하나로 만드는 프리젠테이션
이러한 생성형 AI들은 대부분 딥러닝(Deep Learning) 알고리즘을 기반으로 합니다. 딥러닝은 인공신경망(Artificial Neural Network)을 이용하여 다양한 패턴을 학습하고, 이를 기반으로 새로운 데이터를 생성하거나 분류하는 등의 작업을 수행합니다.
이를 위해서는 먼저 데이터를 수집하고, 이를 전처리(preprocessing)하여 모델의 학습에 적합한 형태로 만들어야 합니다. 이후에는 모델의 구조와 하이퍼파라미터(Hyperparameter)를 설정하고, 학습과 검증을 반복하여 모델의 성능을 개선합니다.
모델의 구현방식은 프로그래밍 언어나 딥러닝 프레임워크에 따라 다를 수 있습니다. 대표적인 딥러닝 프레임워크로는 TensorFlow, PyTorch, Keras, MXNet 등이 있습니다. 이러한 프레임워크를 이용하여 생성형 AI 모델을 구현하고 학습시킬 수 있습니다.

아는 것과 실행은 다른 세상 이야기
– feat by ChatGPT –
이 기사에서는 기본 키 제약 조건이 있는 데이터베이스 열에 가장 적합한 UUID(Universally Unique Identifier) 유형을 살펴보겠습니다.
표준 128비트 임의 UUID가 매우 인기 있는 선택이지만 이것이 데이터베이스 기본 키 열에 적합하지 않다는 것을 알게 될 것입니다.
UUID(Universally Unique Identifier)는 식별자의 고유성을 보장하는 단일 중앙 시스템 없이도 독립적으로 생성할 수 있는 128비트 의사 난수 시퀀스입니다.
RFC 4122 사양은 다양한 데이터베이스 기능 또는 프로그래밍 언어로 구현되는 5가지 표준화된 UUID 버전을 정의합니다 .
예를 들어 UUID()MySQL 함수는 버전 1 UUID 번호를 반환합니다.
그리고 Java UUID.randomUUID()함수는 버전 4 UUID 번호를 반환합니다.
많은 개발자에게 이러한 표준 UUID를 데이터베이스 식별자로 사용하는 것은 다음과 같은 이유로 매우 매력적입니다.
그러나 임의의 UUID를 데이터베이스 테이블 기본 키로 사용하는 것은 여러 가지 이유로 좋지 않습니다.
첫째, UUID는 거대합니다. 모든 단일 레코드는 데이터베이스 식별자로 16바이트가 필요하며 이는 연결된 모든 외래 키 열에도 영향을 미칩니다.
둘째, 기본 키 열에는 일반적으로 조회 또는 조인 속도를 높이기 위해 연결된 B+Tree 인덱스가 있으며 B+Tree 인덱스는 데이터를 정렬된 순서로 저장합니다.
그러나 B+Tree를 사용하여 임의의 값을 인덱싱하면 많은 문제가 발생합니다.
SQL Server 또는 MySQL을 사용하는 경우 전체 테이블이 기본적으로 클러스터된 인덱스 이기 때문에 상황은 더욱 악화됩니다 .
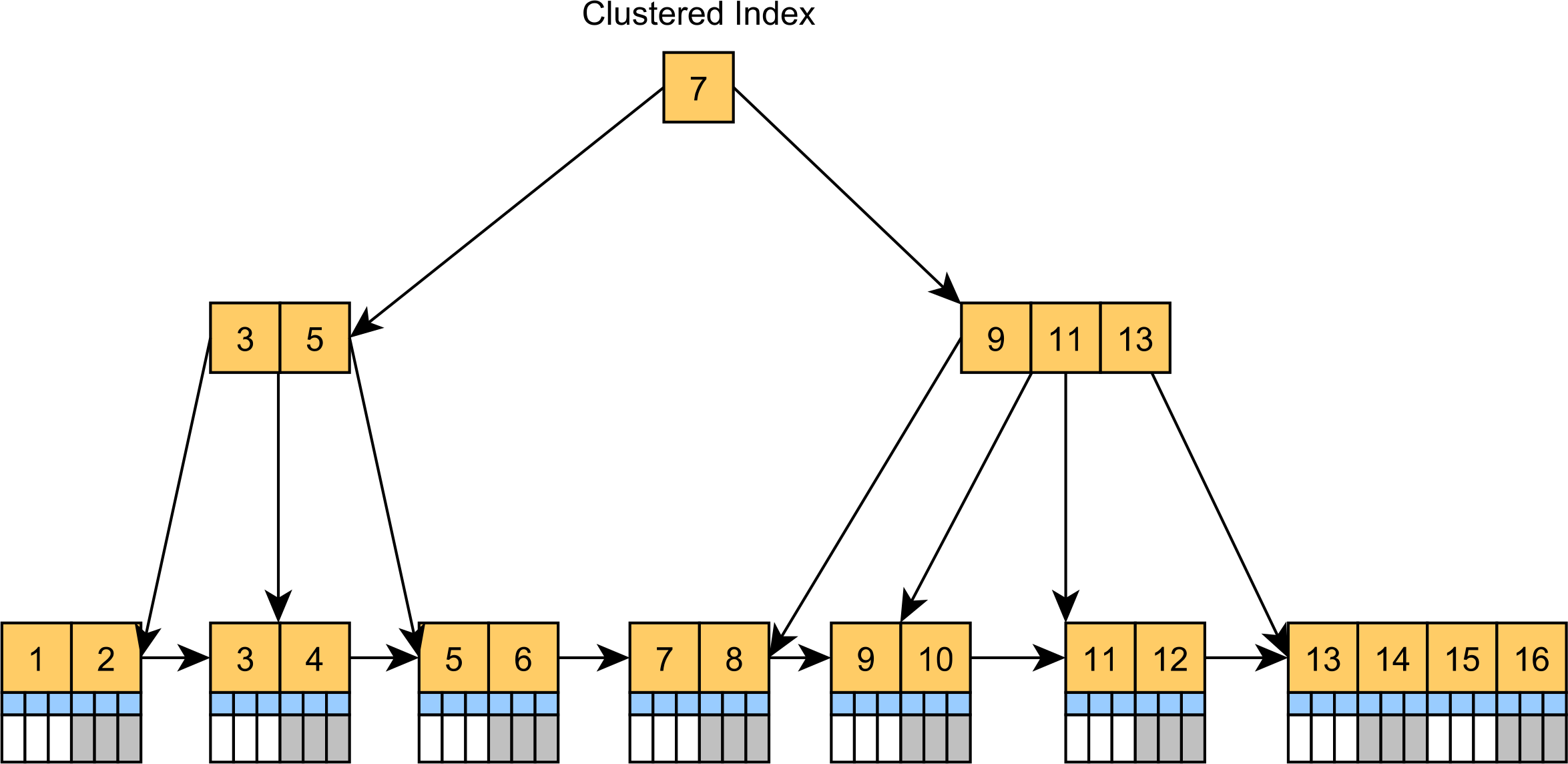
그리고 이러한 모든 문제는 보조 인덱스 리프 노드에 기본 키 값을 저장하기 때문에 보조 인덱스에도 영향을 미칩니다.

실제로 거의 모든 데이터베이스 전문가는 표준 UUID를 데이터베이스 테이블 기본 키로 사용하지 말라고 말합니다.
기본 키 열에 UUID 값을 저장하려는 경우 TSID(시간 정렬 고유 식별자)를 사용하는 것이 좋습니다.
이러한 구현 중 하나 는 다음 두 부분으로 구성된 64비트 TSID를 제공하는 TSID Creator OSS 라이브러리 에서 제공됩니다 .
랜덤 구성 요소는 두 부분으로 구성됩니다.
tsidcreator.node애플리케이션을 부트스트랩할 때 시스템 속성 에서 노드 식별자를 제공할 수 있습니다 .
-Dtsidcreator.node="12"노드 식별자는 TSIDCREATOR_NODE환경 변수를 통해 제공될 수도 있습니다.
export TSIDCREATOR_NODE="12"라이브러리는 Maven Central에서 사용할 수 있으므로 다음 종속성을 통해 가져올 수 있습니다.
<dependency>
<groupId>com.github.f4b6a3</groupId>
<artifactId>tsid-creator</artifactId>
<version>${tsid-creator.version}</version>
</dependency>Tsid다음과 같이 최대 256개의 노드를 사용할 수 있는 개체를 만들 수 있습니다 .
Tsid tsid = TsidCreator.getTsid256();개체 에서 Tsid다음 값을 추출할 수 있습니다.
42– 비트 시퀀스 에 저장된 에포크 이후 Unix 밀리초이러한 값을 시각화하기 위해 로그에 인쇄할 수 있습니다.
long tsidLong = tsid.toLong();
String tsidString = tsid.toString();
long tsidMillis = tsid.getUnixMilliseconds();
LOGGER.info(
"TSID numerical value: {}",
tsidLong
);
LOGGER.info(
"TSID string value: {}",
tsidString
);
LOGGER.info(
"TSID time millis since epoch value: {}",
tsidMillis
);그리고 다음과 같은 결과를 얻습니다.
TSID numerical value: 388400145978465528
TSID string value: 0ARYZVZXW377R
TSID time millis since epoch value: 167043861092710개의 값을 생성할 때:
for (int i = 0; i < 10; i++) {
LOGGER.info(
"TSID numerical value: {}",
TsidCreator.getTsid256().toLong()
);
}값이 단조롭게 증가하는 것을 볼 수 있습니다.
TSID numerical value: 388401207189971936
TSID numerical value: 388401207189971937
TSID numerical value: 388401207194165637
TSID numerical value: 388401207194165638
TSID numerical value: 388401207194165639
TSID numerical value: 388401207194165640
TSID numerical value: 388401207194165641
TSID numerical value: 388401207194165642
TSID numerical value: 388401207194165643
TSID numerical value: 388401207194165644굉장하죠?
유틸리티 를 통해 제공되는 기본 TSID 팩터리는 동기화된 임의 값 생성기와 함께 제공되므로 다음과 같은 최적화를 제공하는 TsidCreator사용자 정의를 사용하는 것이 좋습니다 .TsidFactory
ThreadLocalRandom동기화된 블록에서 스레드 차단을 방지합니다.따라서 새 개체를 생성할 때마다 사용할 수 있도록 TsidUtil다음 을 정의할 수 있습니다 .TsidFactoryTsid
public static class TsidUtil {
public static final String TSID_NODE_COUNT_PROPERTY =
"tsid.node.count";
public static final String TSID_NODE_COUNT_ENV =
"TSID_NODE_COUNT";
public static TsidFactory TSID_FACTORY;
static {
String nodeCountSetting = System.getProperty(
TSID_NODE_COUNT_PROPERTY
);
if(nodeCountSetting == null) {
nodeCountSetting = System.getenv(
TSID_NODE_COUNT_ENV
);
}
int nodeCount = nodeCountSetting != null ?
Integer.parseInt(nodeCountSetting) :
256;
int nodeBits = (int) (Math.log(nodeCount) / Math.log(2));
TSID_FACTORY = TsidFactory.builder()
.withRandomFunction(length -> {
final byte[] bytes = new byte[length];
ThreadLocalRandom.current().nextBytes(bytes);
return bytes;
})
.withNodeBits(nodeBits)
.build();
}
}그리고 동일한 애플리케이션 노드에서 여러 스레드를 사용하는 경우에도 충돌이 발생하지 않는다는 것을 입증하기 위해 다음 테스트 사례를 사용할 수 있습니다.
int threadCount = 16;
int iterationCount = 100_000;
CountDownLatch endLatch = new CountDownLatch(threadCount);
ConcurrentMap<Tsid, Integer> tsidMap = new ConcurrentHashMap<>();
long startNanos = System.nanoTime();
for (int i = 0; i < threadCount; i++) {
final int threadId = i;
new Thread(() -> {
for (int j = 0; j < iterationCount; j++) {
Tsid tsid = TsidUtil.TSID_FACTORY.create();
assertNull(
"TSID collision detected",
tsidMap.put(
tsid,
(threadId * iterationCount) + j
)
);
}
endLatch.countDown();
}).start();
}
LOGGER.info("Starting threads");
endLatch.await();
LOGGER.info(
"{} threads generated {} TSIDs in {} ms",
threadCount,
new DecimalFormat("###,###,###").format(
threadCount * iterationCount
),
TimeUnit.NANOSECONDS.toMillis(
System.nanoTime() - startNanos
)
);이 테스트를 실행하면 다음과 같은 결과를 얻습니다.
16 threads generated 1,600,000 TSIDs in 781 msISID 생성은 충돌이 없었을 뿐만 아니라 800밀리초 이내에 160만 개의 ID를 생성했습니다.
표준 UUID를 기본 키 값으로 사용하는 것은 첫 번째 바이트가 단조롭게 증가하지 않는 한 좋은 생각이 아닙니다.
이러한 이유로 시간 정렬된 TSID를 사용하는 것이 훨씬 더 좋은 생각입니다. 표준 UUID로 절반의 바이트 수를 필요로 할 뿐만 아니라 B+Tree 인덱스 키로 더 적합합니다.
SQL Server는 NEWSEQUENTIALID 를 통해 시간 정렬된 GUID를 제공하지만 GUID의 크기는 128비트이므로 TSID보다 두 배 큽니다.
동일한 문제는 시간 정렬된 UUID를 제공하는 UUID 사양 버전 7 에서도 발생합니다. 그러나 너무 큰 동일한 표준 형식(128비트)을 사용합니다. 기본 키 열 저장소의 영향은 참조하는 모든 외래 키 열에 의해 증폭됩니다.
모든 기본 키가 128비트 UUID인 경우 버퍼 풀이 테이블 페이지와 인덱스 페이지를 모두 보유하므로 디스크와 데이터베이스 메모리 모두에서 기본 키 및 외래 키 인덱스에 많은 공간이 필요합니다.
javax 에서 jakarta로 마이그레이션됩니다GenericApplicationContext(refreshForAotProcessing) 에서 AOT 처리 지원.PathMatchingResourcePatternResolver가 NIO 및 모듈 경로 API를 스캔에 사용하여 각각 GraalVM 네이티브 이미지 및 Java 모듈 경로 내에서 클래스 경로 스캔을 지원합니다.DefaultFormattingConversionService가 ISO 기반 기본 java.time유형 구문 분석을 지원합니다.@HttpExchange 서비스 인터페이스 를 기반으로 하는 HTTP 인터페이스 클라이언트 .PathPatternParser기본적으로 사용됩니다( 옵트인 기능 PathMatcher포함).PartEvent API( 클라이언트 및 서버 모두 ).ResponseEntityExceptionHandler WebFlux 예외를 사용자 지정하고 RFC 7807 오류 응답 을 렌더링하는 새로운 기능 입니다.Flux비스트리밍 미디어 유형에 대한 반환 값(더 이상 List작성 전으로 수집되지 않음).HttpClient는 WebClient.Spring Framework의 여러 부분에서 Micrometer Observation 을 사용한 Direct Observability instrumentation . spring-web모듈은 이제 컴파일 종속성으로 필요 합니다 io.micrometer:micrometer-observation:1.10+.
RestTemplateHTTP 클라이언트 요청 관찰 을 WebClient생성하도록 계측됩니다.org.springframework.web.filter.ServerHttpObservationFilter.org.springframework.web.filter.reactive.ServerHttpObservationFilter.Flux 및 반환 값과의 통합.MonoMockHttpServletRequest, MockHttpSession)는 이제 서블릿 API 6.0을 기반으로 합니다.토르벤 얀센의 아티클 중 참고할 만한 내용을 퍼왔습니다.
https://thorben-janssen.com/6-performance-pitfalls-when-using-spring-data-jpa
먼저 글의 출처를 밝힙니다
이 사이트는 Hibernate와 JPA 의 최신 동향 정보를 확인할 수 있는 괜찮은 사이트입니다.
이 아티클의 내용은 JPA를 사용할 때 성능 문제를 회피하기 위한 6가지 함정을 소개하고 있습니다. 필요한 경우에는 어쩔 수 없이 써야겠지만 함정에 빠지지 않도록 조심해야겠네요.
Spring Data JPA는 퍼시스턴스 레이어를 쉽게 구현할 수 있기 때문에 인기를 얻었습니다. 그러나 여전히 Spring Data JPA, JPA 구현 및 데이터베이스 작동 방식을 이해해야 합니다. 이를 무시하는 것은 성능 문제의 가장 일반적인 이유 중 하나이며 이 기사에서 설명하는 성능 함정에 빠지게 됩니다.
이러한 함정의 대부분을 피하려면 먼저 좋은 로깅 구성을 활성화해야 합니다. Hibernate의 통계는 실행된 모든 작업에 대한 개요를 제공하고 기록된 SQL 문은 데이터베이스와 상호 작용하는 방법을 보여줍니다.
업데이트 작업을 구현할 때 Spring Data JPA의 JpaRepository 에서 제공하는 saveAndFlush 메소드 호출을 피해야 합니다. 그리고 새로운 엔티티에 대한 기본 키 값을 생성할 때, GenerationType.SEQUENCE 를 선호하고 @SequenceGenerator 를 정의하여 Hibernate의 성능 최적화의 이점을 얻어야 합니다. 데이터베이스가 시퀀스를 지원하지 않는다면, Hibernate가 비효율적인 테이블 전략을 사용하는 것을 방지하기 위해 GenerationType.IDENTITY 를 명시적으로 정의해야 합니다.
엔터티 개체를 읽을 때 최상의 성능을 얻으려면 모든 연결의 FetchType 을 LAZY로 정의해야 합니다. 사용 사례에서 엔터티 간의 연결을 트래버스해야 하는 경우 엔터티 개체를 가져올 때 연결을 초기화하도록 지속성 공급자에게 알려야 합니다. 그렇게 하려면 쿼리에 JOIN FETCH 절을 추가하거나 @EntityGraph 주석으로 저장소 메서드에 주석을 추가할 수 있습니다.
또한 읽기 전용 작업에 DTO 프로젝션을 사용하는 경우 연결을 포함하는 복잡한 인터페이스 기반 DTO 프로젝션을 피해야 합니다. 그들은 Spring Data JPA가 DTO 프로젝션 대신 엔티티 프로젝션을 사용하도록 강제합니다.

```dart
import 'package:flutter/material.dart';
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context){
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: const MyHomePage(title: 'Flutter Demo Home Page'),
)
}
}
```
class MyHomePage extends StatefulWidget {
const MyHomePage({super.key, required this.title});
final String title;
@override
State<MyHomePage> createState() => _MyHomePageState();
}
class _MyHomePageState extends State<MyHomePage> {
int _counter = 1;
void _incrementCounter() {
setState(() {
_counter++;
});
}
@override
Widget build(BuildContext context) {
return Container();
}
}

OpenFeign Git, Spring Cloud OpenFeign, Baeldung – Introduction to Spring Cloud OpenFeign
데코레이터는 클래스를 사용하여 만들 수 있고, 결합하여 사용 가능 아래 코드는 CircuitBreaker, RateLimiter 결합하여 사용한 경우
public interface MyService {
@RequestLine("GET /greeting")
String getGreeting();
@RequestLine("POST /greeting")
String createGreeting();
}
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("backendName");
RateLimiter rateLimiter = RateLimiter.ofDefaults("backendName");
FeignDecorators decorators = FeignDecorators.builder()
.withRateLimiter(rateLimiter)
.withCircuitBreaker(circuitBreaker)
.build();
MyService myService = Resilience4jFeign.builder(decorators).target(MyService.class, "http://localhost:8080/");
```</br>데코레이터가 쌓이는 방식
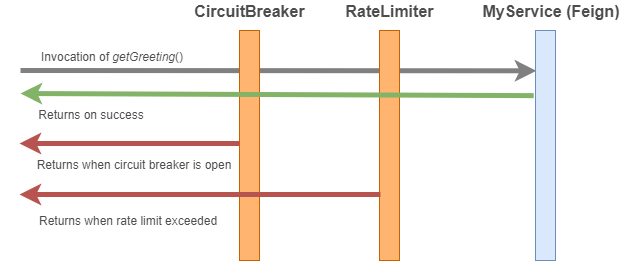
데코레이터 주의사항
// Atype 데코이터 쌓이는 순서 : circuitBreaker -> rateLimiter -> Feign
FeignDecorators decoratorsA = FeignDecorators.builder()
.withCircuitBreaker(circuitBreaker)
.withRateLimiter(rateLimiter)
.build();
// Btype 데코이터 쌓이는 순서 : rateLimiter -> circuitBreaker -> Feign
FeignDecorators decoratorsB = FeignDecorators.builder()
.withRateLimiter(rateLimiter)
.withCircuitBreaker(circuitBreaker)
.build(); public interface MyService {
@RequestLine("GET /greeting")
String getGreeting();
@RequestLine("POST /greeting")
String createGreeting();
}
CircuitBreaker circuitBreaker = CircuitBreaker.ofDefaults("backendName");
RateLimiter rateLimiter = RateLimiter.ofDefaults("backendName");
FeignDecorators decorators = FeignDecorators.builder()
.withCircuitBreaker(circuitBreaker)
.withRateLimiter(rateLimiter)
.build();
this.MyService = Resilience4jFeign.builder(decorators)
.encoder(new JacksonEncoder())
.decoder(new JacksonDecoder())
.target(MyService.class, "http://localhost:8080/"))



